Much like any software, a set of process definitions can grow larger, more complex and more intertwined as time goes. One solution used in the broader software world is encapsulation. This involves pulling out common functionality and breaking up large pieces into smaller components. These same techniques can be used with a set of process definitions. Rather than using copy/paste, sections of process definitions that are common can be extracted. Large process definitions can be split out into smaller components.
Sarasvati supports two ways of doing encapsulation, each with it's own advantages and disadvantages. The first is graph composition , the second is nested processes . Both of these techniques allow complete process definitions and components that have been split out to be defined in separately. The difference lies in when they are composed.
Load-time composition - Graph composition brings the disparate elements together at load time. The main definition being loaded may refer to other definitions. These definitions will be loaded as well and they will all be combined into a single definition. This single definition will execute as if it had been defined in a single file.
Run-time composition - Nested processes use composition at runtime. The main definition will be loaded. When this definition is executed, a node may start a nested process. This nested process will execute and when completed, the main process will continue.
Now that we have general idea of how graph composition and nested processes compare, let us investigate them in more detail.
Graph composition - The set of process definitions may be seen as a single, disconnected graph. A node may contain arcs to nodes in other process definitions. These arcs are referred to as external arcs . When the process definition is loaded, referenced external process definitions will be loaded as well. All the process definitions will be composed into a single, larger graph. The external arcs will become regular arcs. The same external processes definition may be embedded more than once. Each external instance of an external process definition will be given a unique identifier.
Advantages
Interactions with external process definitions are not limited to a single node. The connections may be as complicated as within process definition.
Since the graph is not nested, execution is simple.
All nodes will share a single process variable scope, allowing easy sharing of variables.
Restrictions
Recursion is not allowed, since this would lead to an infinite loop during loading. NOTE: As in regular programing, recursive structures can be implemented using non-recursive techniques.
All nodes will share a single process variable scope. Sometimes it is desirable to have shared state for a subset of the nodes in a process definition.
The version of an external graph is set when the process definition is loaded, rather than when nodes from that graph are executed. If an external process definition is updated, process definitions referring to it must be reloaded as well to pick up the changes.
External Arc - An arc which has an endpoint in an external process definition. While normal arcs are always specified as originating in the node where they are defined (aka out arcs ), it is not possible to add arcs to an external process. Therefore external arcs may either be in arcs or out arcs . Note that external arcs may be named just like regular arcs.
Out Arc - An arc which starts in the defining node and ends in a specified node
In Arc - An arc which starts in a specified node and ends in the node in which it is defined.
External Instance - A specific external process definition may be referenced multiple times. It may also be imported into the referring process definition multiple times, or just a single time. Each external arc names a specific instance of the external process definition.
Nested Process - A node in an executing process may create a separate, new process (of the same or different process definition). This new process is known a nested process. The new process gets initialized with the process state of the containing process and the current token. When the nested process completes, the token in the containing process will be completed.
Advantages
The nested process will have it's own process state
Processes may nested recursively
Nested processes will always use the latest version process definition at the time the node is executed.
Restrictions
The interaction with the nested process must all be contained by a single node. The nested process will execute in isolation. The nodes in the nested process won't interact with the those of the containing process in any way.
Let's look at an examples of how this works in practice. Here is a small process definition which we want to embed. This process definition will be named ext .
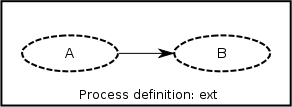
It only has two nodes. Notice that both nodes are using the label-and join strategy, even though one node has no inputs and the other only has one. However, in the composed graph these nodes may have more inputs.
Next is the process definition which will be using ext.
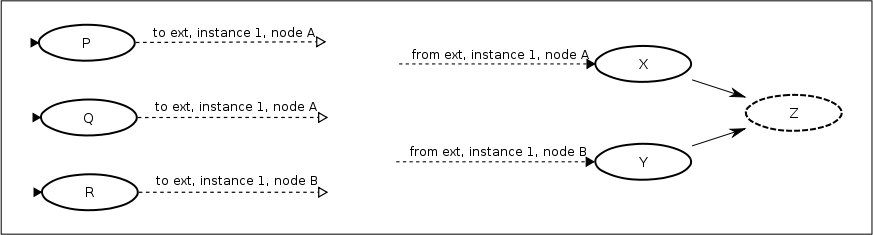
This process definition looks very different from previous examples. It isn't even fully connected.
Some things to note:
The external arcs are labeled with the process definition name, instance and node name that they are intended to link to.
In this case, all the arcs are connecting to the same instance of ext , instance 1.
Both in and out external arcs may connect to any node in the target external. They are not limited to just start nodes, for example.
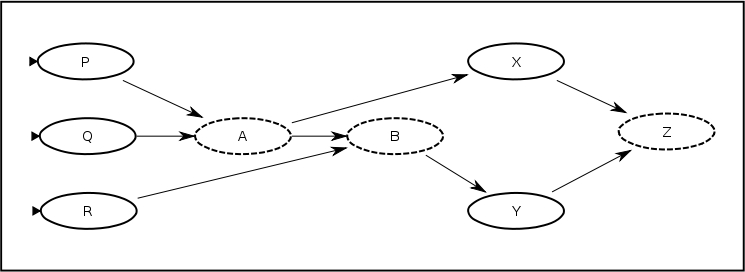
When the graph is loaded, the composed version will look as follows:
The previous example referenced only a single instance. Here is the example using two instances 'ext.
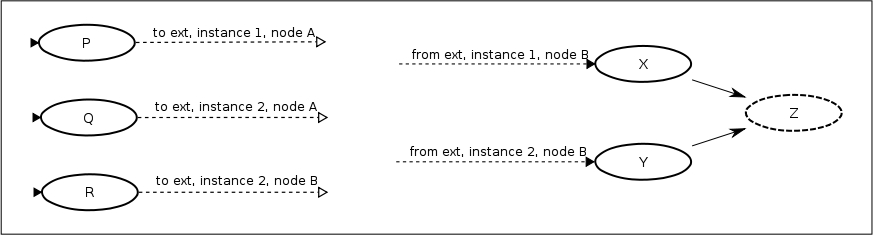
When it is loaded, the composed graph looks like:
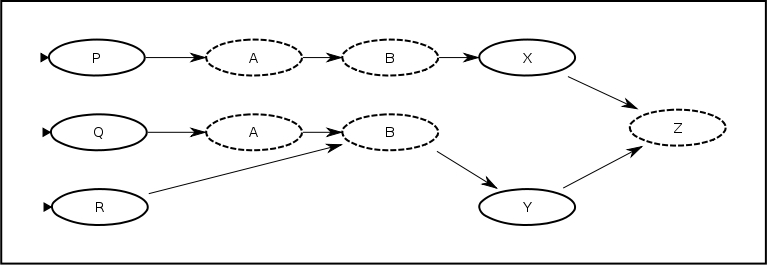
As you can see, we now have two copies of ext embedded in the process definition. One copy will be made for each unique instance referenced. A process definition can have references to any number of different external definitions and each external process definition can be imported any number of times.
The above example could not be implemented with nested processes because a nested process must be represented by a single node in the parent process. So, here is a similar, but simpler example using nested processes.
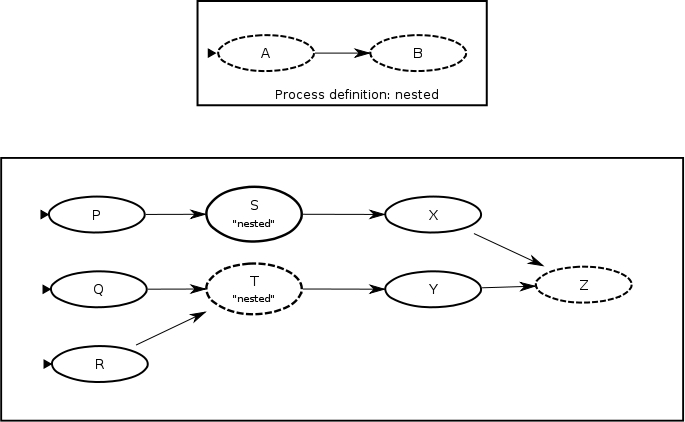
Nodes
S
and
T
both refer to the nested process named
nested
. Note that
nested
is almost the same as
ext
, except that the first node is a start node. This is because
nested
will be executed as a separate process. If it didn't have a
start node, it would not execute.
When
S
and
T
execute, each will spawn a separate process. When
S
is executed, it will have an incomplete node token
t
. As part of execution it will start a new
nested
process
P
which have have the token
t
as a parent. When
P
completes, it will check if it has a parent token, and finding
that it does, will complete
t
. This will allow execution to continue in the original process.